RCCS Reference Manual
[Last update] 2024-Mar-21
This manual is an outdated version. Please refer for the latest version.
Table of Contents
- Connection
- Whole System of RCCS
- RCCS Resources
- Queueing System
- Build and Run
- Package Programs
- Other RCCS Special Commands
- Inquiry
Connection
Login to RCCS
- Frontend nodes (ccfep.ims.ac.jp) can be accessed using ssh with public key authentication.
- All computers will stop during 9:00-19:00 on the first Monday of each month because of maintenance. The maintenance time might be extended.
- Access to frontend nodes is allowed only from IPv4 address assigned to Japan or other registered IP addresses. See Application for SSH connection from outside Japan for details.
Register SSH Public Key and Password for Web
Please prepare a public/private key pair of ssh. If you do not know the procedure, please search in internet by yourself.
First registration / Missing your username or password for web
- Open https://ccportal.ims.ac.jp/en/user/password to request mail for registration in web browser.
- Fill your email which is written in your application, then press button "E-mail new password".
- After you recieve an email from RCCS, open URL in the mail to login in web browser.
- Fill your new password in "Password" and "Confirm password".
- Paste your public key in "Public key".
- Press "Save" button.
Using your username and password for web
- Open https://ccportal.ims.ac.jp/en/frontpage in web browser, then fill your username and password and press "Log in" button.
- Press "My account" which is located in top right corner.
- Press "Edit" tab.
- To change password, fill current password and new passwords.
- Paste your public key.
- Press "Save" button.
Login Shell
- /bin/bash, /bin/tcsh and /bin/zsh are available.
- You can select login shell in the sampe page as ssh public key. It will take some time to change login shell.
- You can custumize your .login or .cshrc in your home directory, but be carefully.
Whole System of RCCS
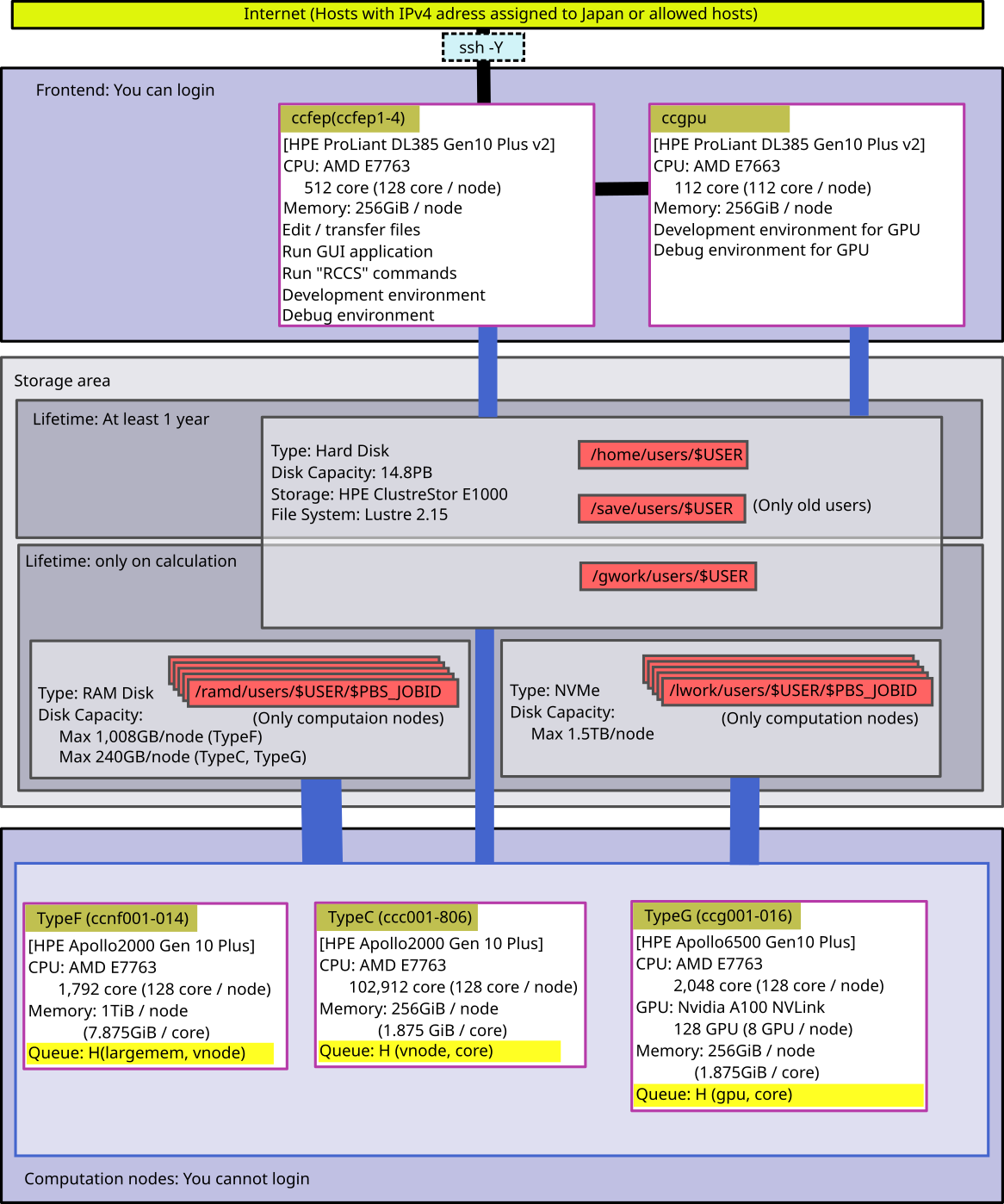
- Whole system of RCCS is shown in the figure below.
- Interactive nodes are ccfep (4 nodes). You can build or debug applications on them.
- There are four kinds of disks, namely /home, /save, /gwork, /lwork(computation node only) and /ramd(computation node only). Access speed and data lifetime are different.
- Width of lines between disks and computers represents transfer speed. Wider is faster.
- Disk /gwork, /lwork and /ramd is temporary space for your calculation. All files will be DELETED after the completion of your job.
- Disk /lwork is NVMe SSD. The capacity is about 1.5 TB. You can use 11.9 GB / core.
- Disk /ramd is RAM disk of each node. The size is about 240 GB or 1,008 GB, depending on node type. The sum of memory used in the job and RAM disk is controlled by the queuing system.
- There are no differences between /home and /save other than the names. (Formerly, there had been a difference regarding backuping policy.)
- Use of /tmp, /var/tmp or /dev/shm is not allowed. Jobs using those dirctories will be killed by the administrator.
- InfiniBand is used for interconnect.
RCCS Resources
CPU Points and Queue Factor
CPU points are spent when you use CPU or GPU.
Queue factors are determined as follows on each systems.
| System | CPU Queue Factor | GPU Queue Factor |
|---|---|---|
| ccap (jobtype=largemem) | 60 points / (1 vnode * 1 hour) | - |
| ccap (jobtype=vnode) | 45 points / (1 vnode * 1 hour) | - |
| ccap (jobtype=core) | 1 point / (1 core * 1 hour) | - |
| ccap (jobtype=gpu) | 1 point / (1 core * 1 hour) | 60 points / (1 GPU * 1 hour) |
- On ccfep, CPU points will be consumed according to CPU time spent.
- On computation nodes, CPU points will be calculated from the elaps of processes.
- We don't charge money for the supercomputer usage.
If you want to know your current CPU points, run "showlim -c".
Checking Resources
- CPU points used by batch jobs and total disk usage (corresponding to "showlim -c" and "showlim -d", respectively) are updated every 10 minutes.
- CPU points used in interactive nodes are updated on 2:20.
- If CPU points run out, all running jobs of your group will be killed and further job submissions won't be allowed.
- If your disk usage exceed the limit, new job submissions will be rejected.
Individulal Limitation of Resources
Access to "Limiting Resources Page" with your web browser.
- Only representative user can limit maximum resources of each members.
- Normal user can only view the values of maximum resources.
- Maximum available number of cpus, point and amount of disks can be limitted.
Queueing System
Overview of Queueing System
![]()
Queue Classes
Queue class for all users
| System | Class (Jobtype) | Node | Memory | Limitation for a job | # of cores per group | # of total vnodes (# of total cores) | ||
|---|---|---|---|---|---|---|---|---|
| Assigned points | # of cores/gpus | # of jobs | ||||||
| ccap | H (largemem) | TypeF | 7.875GB/core | 1-14 vnodes (64-896 cores) | 7,200,000 - 2,400,000 - 720,000 - 240,000 - - 240,000 | 9,600/64 6,400/42 4,096/28 3,200/12 768/8 | 1,000 | 28 vnodes (1,792 cores) |
| ccap | H (vnode) | TypeC | 1.875GB/core | 1-50 vnodes (64-3,200 cores) | 1,248+ vnode (79,872+ cores) | |||
| ccap | H (core) | TypeC | 1.875GB/core | 1-63 cores | 200+ vnodes (12,800+ cores) | |||
| ccap | PN (gpu) | TypeG | 1.875GB/core | 1-48 gpus 1-16 cores/gpu | 32 vnodes (2,048 cores 128 GPUs) | |||
- There are additional limitations for core (ncpus<64 or gpu jobs) and jobtype=largemem jobs. The limit values can be shown by "jobinfo -s" command.
- Jobs must be finished before the scheduled maintenance.
- Only around half of available nodes may accept long jobs (more than a week).
- You can omit jobtype in your jobscript except for jobtype=largemem; other types can be judged from the requested resources.
- 80 nodes of TypeC (160 vnodes) will be shared by "vnode" and "core" jobs.
- Short "vnode" jobs can be assigned to a "largemem" node.
- Short "core" jobs can be assigned to a "gpu" node.
Special queue class
The settings of queue class are following.
| System | Class | Node | Wall Time | Memory | # of cores per job | # of cores per group |
|---|---|---|---|---|---|---|
| ccap | (occupy) | TypeC | 7 days | 4.4GB/core | ask us | allowed number of cores |
Show Job Status
ccfep% jobinfo [-h HOST] [-q QUEUE] [-c|-s|-m|-w] [-n] [-g GROUP|-a] [-n]
choose additional information type
One of those options can be added.
- -c show the latest result (number of GPUs and jobtype etc. are not available)
- -s show status summary of the queue(s)
- -m show memory information
- -w show working directory of jobs
- -n show node status
jobs of other users
- -g group member's jobs are also shown
- If you belong to multiple groups, try -g [GROUP name] to specify a group.
- -a show all users' jobs
- most of information (username etc.) will be hidden.
queue specification
You don't need to specify this usually, since all the user available queues (H and HR[0-9]) are the default targets.
- -h HOST: specify host type (only ccap is available)
- -q QUEUE: specify queue name (such as H or HR1)
Example: show queue summary
In User/Group stat, number of jobs, cpu cores, and gpus can be shown by "jobinfo -s". Limitation about those resources are also shown. In Queue Status, number of waiting jobs and available nodes/cores/gpus will be shown.
ccfep% jobinfo -s
User/Group Stat:
--------------------------------------------------------------------------------
queue: H | user(***) | group(***)
--------------------------------------------------------------------------------
NJob (Run/Queue/Hold/RunLim) | 1/ 0/ 0/- | 1/ 0/ 0/6400
CPUs (Run/Queue/Hold/RunLim) | 4/ 0/ 0/- | 4/ 0/ 0/6400
GPUs (Run/Queue/Hold/RunLim) | 0/ 0/ 0/- | 0/ 0/ 0/ 48
core (Run/Queue/Hold/RunLim) | 4/ 0/ 0/1200 | 4/ 0/ 0/1200
--------------------------------------------------------------------------------
note: "core" limit is for per-core assignment jobs (jobtype=core/gpu*)
Queue Status (H):
----------------------------------------------------------------------
job | free | free | # jobs | requested
type | nodes | cores (gpus) | waiting | cores (gpus)
----------------------------------------------------------------------
week jobs
----------------------------------------------------------------------
1-4 vnodes | 705 | 90240 | 0 | 0
5+ vnodes | 505 | 64640 | 0 | 0
largemem | 0 | 0 | 0 | 0
core | 179 | 23036 | 0 | 0
gpu | 0 | 0 (0) | 0 | 0 (0)
----------------------------------------------------------------------
long jobs
----------------------------------------------------------------------
1-4 vnodes | 325 | 41600 | 0 | 0
5+ vnodes | 225 | 28800 | 0 | 0
largemem | 0 | 0 | 0 | 0
core | 50 | 6400 | 0 | 0
gpu | 0 | 0 (0) | 0 | 0 (0)
----------------------------------------------------------------------
Job Status at 2023-01-29 17:40:12
"core (Run/Queue/Hold/RunLim)" in User/Group Stat is a CPU cores limit for jobtype=core/gpu* jobs, where CPU cores used by jobtype=vnode/largemem jobs are not taken into account. For example, in this example, you can use up to 1200 cores in total.
Example: show status of jobs
You can see the latest status of jobs by specifying "-c" option. (-l option can be added but is ignored.)
ccfep% jobinfo -c
--------------------------------------------------------------------------------
Queue Job ID Name Status CPUs User/Grp Elaps Node/(Reason)
--------------------------------------------------------------------------------
H 9999900 job0.csh Run 16 zzz/--- 24:06:10 ccc047
H 9999901 job1.csh Run 16 zzz/--- 24:03:50 ccc003
H 9999902 job2.sh Run 6 zzz/--- 0:00:36 ccc091
H 9999903 job3.sh Run 6 zzz/--- 0:00:36 ccc091
H 9999904 job4.sh Run 6 zzz/--- 0:00:36 ccc090
...
H 9999989 job89.sh Run 1 zzz/--- 0:00:11 ccg013
H 9999990 job90.sh Run 1 zzz/--- 0:00:12 ccg010
--------------------------------------------------------------------------------
If you don't specify "-c", you can also see some more details (jobtype and number of gpus). The information may be slightly (2-3 minutes usually) old, though.
ccfep% jobinfo
--------------------------------------------------------------------------------
Queue Job ID Name Status CPUs User/Grp Elaps Node/(Reason)
--------------------------------------------------------------------------------
H(c) 9999900 job0.csh Run 16 zzz/zz9 24:06:10 ccc047
H(c) 9999901 job1.csh Run 16 zzz/zz9 24:03:50 ccc003
H(c) 9999902 job2.sh Run 6 zzz/zz9 0:00:36 ccc091
H(c) 9999903 job3.sh Run 6 zzz/zz9 0:00:36 ccc091
H(c) 9999904 job4.sh Run 6 zzz/zz9 0:00:36 ccc090
...
H(g) 9999989 job89.sh Run 1+1 zzz/zz9 0:00:11 ccg013
H(g) 9999990 job90.sh Run 1+1 zzz/zz9 0:00:12 ccg010
--------------------------------------------------------------------------------
Example: show working directory
In case you forget where you ran jobs, try "-w" option. The working directories will be shown like below.
ccfep% jobinfo -w
--------------------------------------------------------------------------------
Queue Job ID Name Status Workdir
--------------------------------------------------------------------------------
H 9999920 H_12345.sh Run /home/users/zzz/gaussian/mol23
H 9999921 H_23456.sh Run /home/users/zzz/gaussian/mol74
...
(You can't use "-c" in this case.)
Submit Your Jobs
Description of the header part
Your have to write a script file which is written in C-shell to submit your job. An example for each system is following.
- csh, bash (/bin/sh), zsh can be used for the job submission script.
- lines started with #PBS are common, regardless of the shell type.
- Sample scripts can be found in ccfep:/local/apl/lx/(application name)/samples/.
| Meaning | Header part | Importance |
|---|---|---|
| The First Line | (csh) #!/bin/csh -f (bash) #!/bin/sh (zsh) #!/bin/zsh | Required (choose one) |
| Needed Number of CPU | #PBS -l select=[Nnode:]ncpus=Ncore:mpiprocs=Nproc:ompthreads=Nthread:jobtype=Jobtype[:ngpus=Ngpu] | Required |
| Wall Time | #PBS -l walltime=72:00:00 | Required |
| Mail at Start and End | #PBS -m abe | Optional |
| Prevent Rerun | #PBS -r n | Optional |
| Change to Submitted Directory | cd ${PBS_O_WORKDIR} | Recommended |
- Nnode: # of physical node or virtual node
- Ncore: # of reserved cores per physical node or virutal node
- largemem, vnode: 64 (for virtaul node) or 128 (for physical node)
- Nproc: # of processes per node
- Nthread: # of threads per process
- Jobtype: largemem, small, core, gpu, gpup, gpuv
- large: 7.875GB / core
- vnoe: 1.875GB / core
- core: job for less than 63 cores
- gpu: GPU jobs
- Ngpu: # of GPUs
example 1: use 5 nodes (640 (128*5) cores, 320 (64*5) MPI)
#PBS -l select=5:ncpus=128:mpiprocs=64:ompthreads=2
example 2: use 10 vnodes (64 for each) (640 (64*10) cores, 320(32*10) MPI)
#PBS -l select=10:ncpus=64:mpiprocs=32:ompthreads=2
example 3: 16-core (16 MPI)
#PBS -l select=1:ncpus=16:mpiprocs=16:ompthreads=1
example 4: 16-core (16 OpenMP) + 1 GPU
#PBS -l select=1:ncpus=16:mpiprocs=1:ompthreads=16:ngpus=1
note: there are 8 GPUs in a node. # of CPU cores per GPU (ncpus/ngpus) must be <= 16.
example 5: 64 cores (1 vnode), large memory node (~500 GB of memory / vnode)
#PBS -l select=1:ncpus=64:mpiprocs=32:ompthreads=2:jobtype=largemem
You can find some other examples in this page.
Job submission
After you write the script, type following command to submit.
ccfep% jsub [-q HR[0-9]] [-g XXX] [-W depend=(afterok|afterany):JOBID1[:JOBID2...]] script.csh
- If you run too many jobs in a short period of time, penalty might be imposed. If you are planning to run thousands of jobs in a day, please merge them.
- If you want to submit your jobs by 'Supercomputing Consortium for
Computational Materials Science ' group, use -g option. (XXX is name of its group) - You can describe dependency of jobs using -W option.
- If you want to describe dependency that a job should run after the dependent job exit successfully, use keyword "afterok".If a job should run after the dependent job including abnormal exit, use keyword "afterany".
- Sample script files exist in ccfep:/apl/*/samples/.
Sequential Jobs (step jobs)
You can easily submit sequential jobs by using --step or --stepany command.
step job 1 (afterok): run a series of jobs sequentially. If a job exited abnormally, following jobs will be deleted.
ccfep% jsub -q (H|HR[0-9]) [-g XXX] --step [-W depend=(afterok|afterany):JOBID1[:JOBID2...]] script.csh script2.csh ...
step job 2 (afterany): run a series of jobs sequentially. If a job finished, next job will run regardless of the exit status.
ccfep% jsub -q (H|HR[0-9]) [-g XXX] --stepany [-W depend=(afterok|afterany):JOBID1[:JOBID2...]] script.csh script2.csh ...
Example:
ccfep% jsub -q H --stepany job1.csh job2.csh job3.csh
Define variables which can be used in jobscript
You can define variables via -v option. The argument to the option is comma-separated list of variable definitions, (variable-name)=(value).
ccfep% jsub -v INPUT=myfile.inp,OUTPUT=myout.log script.sh
In this example, $INPUT and $OUTPUT will be set to myfile.inp and myout.log in "script.sh", respectively.
Notes:
- if multiple -v is specified, only the last one will be active.
- this can't define ncpus, jobtype etc. values in select= section of the jobscript.
Delete Jobs
First of all, you should get ID of the target jobs using "jobinfo" command. Then, run following command, where the RequestID is the job id.
ccfep% jdel RequestID
Hold/Release Jobs
You can prevent queued job to run by the following command (hold a job, in other words). (Use jobinfo to get target job id.)
ccfep% jhold RequestID
You can release the restiction using jrls command.
ccfep% jrls RequestID
Get Information of Finished Jobs
You can get information of finished jobs, such as finish time, elaps time, parallel efficiency, by joblog command.
ccfep% joblog [-d ndays] [-o item1[,item2[,...]]]
If the target period is not specified, information about jobs of current FY will be shown. Following options can be used to specify the target period.
- -d ndays: jobs finished within last "ndays"
- -d 7 : jobs finished within last 7 days
- -y year: jobs in FY "year"
- -y 2021 : jobs in FY 2021 (2021/4-2022/3)
- -f YYYY[MM[DD[hh[mm]]]] -t YYYY[MM[DD[hh[mm]]]]: from-to specification. (month, day, hour, etc. can be omitted)
- -f 202107 -t 202108 : jobs finished in July or August of year 2021.
You can customize items which are displayed in -o option. Available keywords are:
- queue: Queue name
- jobid: Job ID
- user: User name
- group: Group name
- node: Job head node name
- Node: All node names
- type: jobtype
- start: Start time(YYYY/MM/DD HH:MM)
- Start: Start time(YYYY/MM/DD HH:MM:SS)
- finish: Finish time(YYYY/MM/DD HH:MM)
- Finish: Finish time(YYYY/MM/DD HH:MM:SS)
- elaps: Elaps
- cputime: Total CPU time
- used_memory: Used memory size
- ncpu: Number of reserved cpu cores
- ngpu: Number of reserved gpus
- nproc: Number of MPI processes
- nsmp: Number of threads per process
- peff: Efficiency of job
- attention: Bad efficiency job
- command: Job name
- point: CPU points
- all: show all
e.g. 1: Show job ID, start and end datetime, CPU points of jobs finished within last 10 days.
ccfep% joblog -d 10 -o jobid,start,finish,point
e.g. 2: Show job ID, end datetime, CPU points, and workding directory of jobs in FY2020.
ccfep% joblog -y 2020 -o jobid,finish,point,Workdir
e.g. 3: Show all the parameters of jobs finished within last two days.
ccfep% joblog -d 2 -o all
Build and Run
Command to Build
- gcc, aocc, NVIDIA HPC SDK are already installed.
- For Intel oneAPI, only the libraries are installed. Compilers (icc, ifort, icpc etc.) are not installed. If you need Intel compilers, please install oneAPI Base Toolkit or/and oneAPI HPC Toolkit by yourself into your directory.
- For gcc, system default one (8.5) and gcc-toolset ones (versions 9.2, 10.3, and 11.2) are installed. You can use gcc-toolset gccs by module command. (e.g. module load gcc-toolset/11)
Please also check the package program list page for the available libraries and MPI environments.
How to load my oneAPI environment
oneAPI Base Toolkit can be downloaded from this page. Compilers, MKL, and MPI are included. Please use offline or online one for Linux. You need to install oneAPI HPC Toolkit if you need fortran compiler (ifort, ifx). Please download from this page.
For bash users, following module method can work. But just loading ~/intel/oneapi/setvars.sh is easier.
You can use individual component of oneAPI such as compilers and MKL by loading "vars.sh" file in each component directory.
(e.g. source ~/intel/oneapi/compiler/latest/env/vars.sh)
We here introduce a simple way using module command. There maybe several ways to do it.
It is assumed that oneAPI is already installed under ~/intel.
$ cd ~/intel/oneapi
$ sh modulefiles-setup.sh
$ cd modulefiles/
$ module use .
$ module save
This will gather oneapi module files into modulesfiles/ directory and that directory is registered in the module search path.
Final module save command saves the setting. The saved environment will be restored upon login in RCCS system.
If you want to use Intel compilers, you need to run "module load compiler/latest".
(Please check "module avail" for details about packages and their versions.)
You can load compilers and other packages before "module save".
In this case, you can use compilers and libraries immediately after your next login.
$ cd modulefiles/
$ module use .
$ module load compiler/latest
$ module load mkl/latest
$ module load mpi/latest
$ module save
If you want to remove saved module environment, please try "module saverm". Please note that your saved environment is independent from the system default setting. Changes in the system default setting do nothing to your environment.
Running Parallel Program
Please specify correct numbers of MPI processes and OpenMP threads in "mpiprocs" and "ompthreads" values of select line in your job script.
e.g. 12 CPUs, 4 MPI processes and 3 OpenMP threads case -> ncpus=12:mpiprocs=4:ompthreads=3
Please also check sample jobs scripts by RCCS (locating at /apl/(software name)/samples ).
Number of threads specification for OpenMP jobs
When submitting job using "jsub", the value specified by "ompthreads" is considered as number of OpenMP threads.
You can specify or change the value by setting OMP_NUM_THREADS envirnment variable manually.
If you run a command not via "jsub" (on frontend node for example), you should set OMP_NUM_THREADS environment variable manually.
Host list specification for MPI
List of hosts can be found in the file name specified in PBS_NODEFILE environment variable.
MPI environments installed by RCCS (Intel MPI and OpenMPI) automatically consider this environment variable.
Therefore, you can skip specification of machine file when invoking "mpirun" command.
e.g. 4 MPI * 3 OpenMP hybrid parallel
#!/bin/sh
#PBS -l select=1:ncpus=12:mpiprocs=4:ompthreads=3:jobtype=core
#PBS -l walltime=24:00:00
cd $PBS_O_WORKDIR
mpirun -np 4 /some/where/my/program options
- OpenMP thread number is determined from the value specified by "ompthreads" in select. (equivalent to OMP_NUM_THREADS=3)
- MPI machine file name can be omitted when invoking mpirun (if that mpirun is installed by RCCS).
- You can specify machine file to filename specified in PBS_NODEFILE env variable. (This doesn't change anything.)
Environment Modules
- In jobscript, csh users need to run "source /etc/profile.d/modules.csh" before using module command.
- In the jobscript, "source /etc/profile.d/modules.csh" is necessary for /bin/bash users.
- ". /etc/profile.d/modules.sh" is necessary for /bin/sh or /bin/bash jobscript if your login shell is /bin/csh
- You should add -s to module command in the script. (e.g. module -s load openmpi/3.1.6)
- You can save current module status by "module save" command. The saved status will be restored automatically upon login.
- In case "setvars.sh" is loaded in ~/.bashrc, sftp (including WinSCP) failed to connect to ccfep due to the output from that script.
- You may be able to avoid this error by discarding output from setvars.sh like "source ~/intel/oneapi/setvars.sh >& /dev/null"
- (Load setvars.sh only if $PS1 is not null should work. Just move that line to ~/.bash_profile may also work.)
- See this page for detailed information.
Package Programs
- The installed pacakge programs for each systems are listed in https://ccportal.ims.ac.jp/en/installed_applications.
- You can see the similar list by "module avail" command. (To quit module avail, press "q" key or scroll to the bottom of the page.)
- Sample script files are located in ccfep:/apl/appname/samples/.
- Installed directories are located in /apl/appname/ on each systems.
- Applications compiled by center are listed in https://ccportal.ims.ac.jp/en/how_to_configure with detail description.
- Many software is quitting preparation of config script in csh. We recommend csh users to use module command.
Request installation you want to use
Please fill the following items and send it rccs-admin[at]ims.ac.jp.
- Software name and version that you want to use
- Overview of the software and its feature
- Necessity of installation to supercomputers in RCCS
- URL of the software development
Special Commands of RCCS
Related Queueing System
You can find descriptions about "jobinfo", "jsub", "jdel", "jhold", "jrls", and "joblog" above in this page.
Submitting Gaussian Jobs
Case of Gaussian 16
ccfep% g16sub [-q "QUE_NAME"] [-j "jobtype"] [-g "XXX"] [-walltime "hh:mm:ss"] [-noedit] \
[-rev "g16xxx"] [-np "ncpus"] [-ngpus "n"] [-mem "size"] [-save] [-mail] input_files
- Command "g09sub" are also available to use Gaussian 09.
- Default walltime is set to 72 hours. Please set excepted time for calculation and extra to do long job or run early.
- If you want to know the meaning of options and examples, please just type "g16sub".
- %mem, %nproc, %cpu in the original input files will be overwritten by g16sub / g09sub. Please specify those values with -mem, -np etc. command line options.
- You can prevent this automatic overwrite by -noedit option. But this is not recommended.
- Safe maximum %mem value will be automatically assigned by g09sub/g16sub. You may not need to set that manually unless you need to reduce the amount of memory.
- If you want to use large memory node (jobtype=largemem) you need to add "-j largemem".
- Jobtype=vnode will be used if -np 64 or -np 128 is specified.
basic usage ( 8 cores、72 hours)
[user@ccfep somewhere]$ g16sub input.gjf
more cores, more longer (16 cores、168 hours)
[user@ccfep somewhere]$ g16sub -np 16 --walltime 168:00:00 input.gjf
To use formchk, please check this FAQ item.
Job wait time estimator (waitest)
On ccfep, you can estimate start time of job with "waitest" command, where waitest assumes jobs will run for the time specified with "walltime" parameter". Therefore, the estimated datetime will be the worst case estimation. On the other hand, other user's jobs submitted later might run earlier than your ones. (Many parameters, such as job priority, jobtype, and remedies for (small) groups, are involved.) You shouldn't expect high accuracy for the estimation. You may also need to check queue status (jobinfo -s) additionally.
Basic Usage
Estimate start time of submitted job(s):
$ waitest [jobid1] ([jobid2] ...)
Estimate start time of not yet submitted job(s):
$ waitest -s [job script1] ([jobscript2] ...)
Example 1: estimate start time of a submitted job
[user@ccfep2]$ waitest 4923556
Current Date : 2023-02-15 14:32:30
2023-02-15 14:32:30 ...
2023-02-15 16:40:44 ...
2023-02-15 22:26:07 ...
2023-02-16 00:43:43 ...
2023-02-16 03:03:11 ...
2023-02-16 05:58:00 ...
2023-02-16 11:34:12 ...
Job 4923556 will run at 2023-02-16 13:03:11 on ccc500.
Estimation completed.
Example 2: estimate start time of not yet submitted jobs
[user@ccfep2]$ waitest -s vnode4N1D.sh vnode1N1D.sh
Job Mapping "vnode4N1D.sh" -> jobid=1000000000
Job Mapping "vnode1N1D.sh" -> jobid=1000000001Current Date : 2023-09-06 16:43:10
2023-09-06 16:43:10 ...
2023-09-06 18:43:42 ...
2023-09-06 21:19:19 ...
Job 1000000001 will run at 2023-09-06 21:39:34 on ccf013.
2023-09-06 22:02:09 ...
2023-09-07 01:02:14 ...
2023-09-07 03:34:18 ...
Job 1000000000 will run at 2023-09-07 05:28:07 on ccc428,ccc571,ccc356,ccc708.
Estimation completed.
(In some case, larger jobs will run first due to the job priority and other parameters.)
Example 3: show periodically estimated wait time for general types of jobs
For some of basic types of jobs, wait time for those jobs are estimated periodically. The result can be accessed via the following command.
[user@ccfep2]$ waitest --showref
Showing Used Resources
ccfep% showlim (-cpu|-c|-disk|-d) [-m]
- -cpu|-c: Show used point and limited value.
- -disk|-d: Show current disk size and limited value.
- -m: Show values of each members.
example 1: show CPU points (approved and used) of YOU and WHOLE YOUR GROUP
ccfep% showlim -c
example 2: show CPU points (approved and used) of YOU, YOUR GROUP MEMBERS, and WHOLE GROUP
ccfep% showlim -c -m
example 3: show disk status (approved and used) of YOU, YOUR GROUP MEMBERS, and WHOLE GROUP
ccfep% showlim -d -m
Utility Commands for Batch Jobs
Limit the walltime of command
- ps_walltime command which was provided from RCCS was deleted. Please use timeout command instead.
Showing statistic of current job
- jobstatistic command which was provided from RCCS was deleted. Please use joblog command instead.
Manipulation of Files on Computation Nodes
You can access local files on computation nodes which cannot be directly accessed from the frontend nodes (ccfep) via "remsh" command.
remsh hostname command options
- hostname: Hostname such as cccc???, cccca???, ccnn???, or ccnf???.
- command: Command to be executed on the node. Acceptable commands are ls, cat, cp, head, tail, and find.
- options: Options of command.
Example: how to access ramdisk of a computation node, ccnnXXX, by user "zzz"
remsh ccnnXXX ls /ramd/users/zzz
remsh ccnnXXX tail /ramd/users/zzz/99999/fort.10
Host names and jobids of your jobs can be found in the output of "jobinfo" command. (see above for the usage)